

Benchmarks



AIDA64 verfügt über mehrere Benchmarks, die eingesetzt werden können, um die Leistung der einzelnen Hardwarekomponenten bzw. des Systems als Ganzes zu messen. Es handelt sich dabei um synthetische Benchmarks, was bedeutet, dass diese verwendet werden können, um die theoretisch maximale Leistung des Systems zu messen. Die Tests, die die Leistung des Prozessors (CPU) und die Einheit für die Berechnung der Fließkomma-Operationen (FPU) messen, basieren auf der Multi-Thread AIDA64 Benchmark-Engine, die – seit AIDA64 Business v4.00 – bis zu 640 gleichzeitige Verarbeitungsthreads und 10 Prozessorgruppen unterstützen kann. Die Engine bietet volle Unterstützung für die Multi-Prozessor (SMP), Multi-Core und HyperTheading Technologien.
Geschwindigkeit von Cache, Speicher und Datenträger
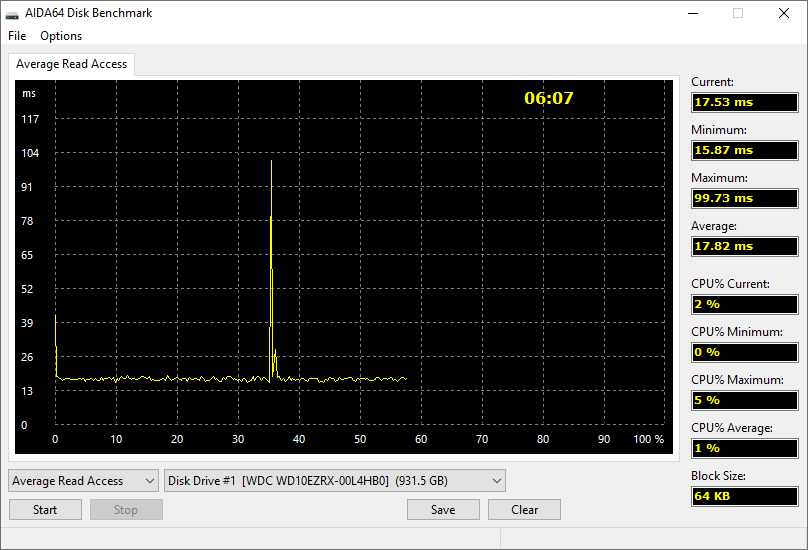
AIDA64 bietet ein eigenes Modul für die Messung der Lese-, Schreib- und Kopiegeschwindigkeit von Speicher und Cache, sowie für die Überprüfung der Datentransfergeschwindigkeit des Datenträgers. Mit dem letzteren Modul ist es möglich, nicht nur die Leistung der Festplatten zu messen sondern auch RAID-Blöcke, optische Laufwerke, ZIP-Laufwerke, Solid-State-Drives (SSD), USB-Sticks, Speicherkarten und Flash Speichergeräte zu testen.
GPGPU Benchmark
Dieses Benchmark-Modul, das aus der Werkzeuge | GPGPU Benchmark gestartet werden kann, bietet eine Reihe von OpenCL GPGPU Benchmarks. Mit Hilfe dieser Benchmarks kann die GPGPU Leistung mit verschiedenen OpenCL Belastungen gemessen werden. Jede einzelne Benchmark kann auf bis zu 16 GPUs, darunter AMD, Intel und NVIDIA-GPUs (oder eine Kombination von diesen) betrieben werden. Natürlich werden Crossfire-und SLI-Konfigurationen sowie die beiden APUs und dGPUs vollständig unterstützt. Grundsätzlich kann jedes Gerät, das als ein GPU unter den OpenCL-Geräten aufgeführt ist, verglichen werden.
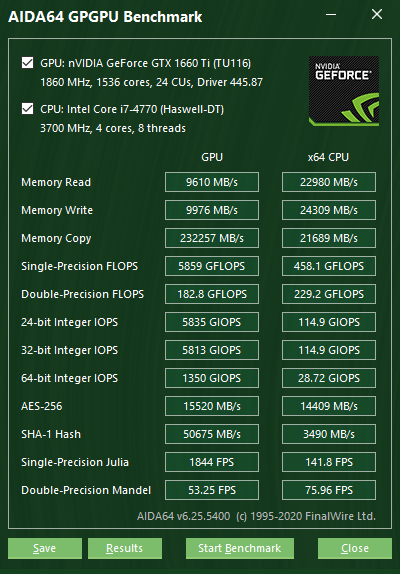
Zusätzlich zu diesen umfassenden Benchmarks bietet AIDA64 geeignete Mikro-Benchmarks, die im Seitenmenü unter der Benchmark-Kategorie zur Verfügung stehen. Dank der sehr großen Referenzergebnisdatenbank von AIDA64 können die Benchmark-Ergebnisse mit jenen anderer Konfigurationen verglichen werden. Im Moment stehen die folgenden Mikro-Benchmarks zur Verfügung:
Speicher-Benchmarks
Speicher-Benchmarks messen die maximale Datentransfergeschwindigkeit, die erreicht werden kann, wenn die ausgewählten Operationen (lesen, schreiben, kopieren) durchgeführt werden. Diese sind in Assembly geschrieben und sind für die bekannten AMD, Intel und VIA Prozessor-Core-Variante durch die Verwendung von x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX sowie AVX2 Befehlssatzerweiterungen bestmöglich optimiert.
Die Speicherverzögerungs-Benchmark misst die typische Verzögerung, bis der Prozessor die vom Speicher angeforderten Daten erhält. Unter Verzögerung versteht man also die Zeit, die zwischen der Erteilung des Lesebefehls und dem Eingang der Daten ins Integer-Register des Prozessors vergeht.
CPU Queen

Dieser einfache Integer-Benchmark berechnet Lösungen für das klassische “N queens puzzle” auf einem 10x10 Schachbrett. In der Theorie erreicht der Prozessor mit der gleichen Taktfrequenz mit einer kürzeren Pipeline und weniger Misprediction Penalties höhere Benchmark-Ergebnisse. Der Intel Northwood basierte Pentium 4 Prozessor erreicht mit deaktiviertem HyperThreading bessere Ergebnisse als die Intel Prescott Prozessoren, da der zuerst Genannte eine 20-stufige Pipeline, wohingegen der zuletzt Genannte eine 31-stufige Pipeline hat. CPU-Queen verwendet integer MMX, SSE2 und SSSE3 Optimierungen.
CPU PhotoWorxx

Diese Integer-Benchmark misst die Leistung des Prozessors mit mehreren 2D Fotobearbeitungsalgorithmen. Sie führt die folgenden Aktionen an einem sehr großen RGB-Bild durch:
- Befüllt das Bild mit zufälligen Farbpixeln
- Drehung um 90 gegen den Uhrzeigersinn
- Drehung um 180 Grad
- Differenz
- Farbraumumkonvertierung (verwendet z. B. während der JPEG-Konvertierung)
Der Test hebt hauptsächlich die SIMD-Integer-Rechenwerke des Prozessors und das Speicher-Subsystem hervor. Der CPU PhotoWorxx Test nutzt die geeigneten x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2 und XOP Befehlssatzerweiterungen und ist NUMA, HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) geeignet.
CPU ZLib
Diese Integer-Benchmark misst die kombinierte Leistung des CPU- und Speichersubsystems mit der ZLib Kompressionsbibliothek. Der CPU ZLib Test verwendet auschließlich x86 Befehle und unterstützt HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) Architekturen.
CPU AES
Diese Integer-Benchmark misst die Leistung des Prozessors mithilfe der AES (Advanced Encryption Standard) Datenverschlüsselung. In der Kryptografie ist AES ein Verschlüsselungsstandard mit symmetrischem Schlüssel. AES wird heute bei mehreren Komprimierungs-Tools wie z. B. 7z, RAR, WinZip und auch in Festplattenverschlüsselungen wie BitLocker, FileVault (Mac OS X), TrueCrypt eingesetzt. CPU AES verwendet die geeigneten x86, MMX und SSE4.1 Befehle und es ist Hardware-beschleunigt auf VIA PadLock Security Engine-fähigen VIA C3, VIA C7, VIA Nano und VIA QuadCore Prozessoren sowie Intel AES-NI befehlssatzerweiterungs-fähigen Prozessoren. Die Benchmark ist HyperThreading-, Multi-Prozessor (SMP) und Multi-Core (CMP) geeignet.
CPU Hash
Diese Integer-Benchmark misst die Leistung des Prozessors mithilfe des SHA1 Hashing-Algorithmus, wie es in den Federal Information Processing Standards Publication 180-4 dargelegt ist. Der Code hinter dieser Benchmark-Methode ist in Assembly geschrieben und ist für alle gekannten AMD, Intel und VIA Prozessoren durch die geeigneten MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI, und BMI2 Befehlssatzerweiterungen optimiert. Die CPU-Hash-Benchmark ist Hardware-beschleunigt auf VIA PadLock Security Engine-fähigen VIA C7, VIA Nano und VIA QuadCore Prozessoren.
FPU VP8
Diese Benchmark misst die Videokompressionsleistung (http://www.webmproject.org/) unter Verwendung des Google VP8 (WebM) 1.1.0 Codecs. Es verschlüsselt 1280x720 Pixel („HD-fähig“) Video-Frames im 1-Pass-Modus mit einer Bitrate von 8192 kbps mit besten Qualitätseinstellungen. Der Inhalt der Frames wird über das FPU Julia Fractal Modul erstellt. Der Code hinter dieser Benchmark-Methode verwendet die geeigneten MMX, SSE2, SSSE3 bzw. SSE4.1 Befehlssatzerweiterungen und ist HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) geeignet.
FPU Julia

Diese Benchmark misst die 32-Bit Fließkommaberechnungsleistung durch die Berechnung mehrerer “Julia” Fraktale. Der Code hinter dieser Benchmark ist in Assembly geschrieben und ist für alle bekannten AMD, Intel und VIA Prozessoren mithilfe der geeigneten x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA und FMA4 Befehlssatzerweiterungen optimiert. FPU Julia unterstützt HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) Architekturen.
FPU Mandel

Diese Benchmark misst die 64-bit Fließkommaberechnungsleistung durch die Berechnung mehrerer “Mandelbrot” Fraktale. Der Code hinter dieser Benchmark ist in Assembly geschrieben und ist für alle bekannten AMD, Intel und VIA Prozessorkernvarianten mithilfe der geeigneten x87, SSE2, AVX, AVX2, FMA und FMA4 Befehlssatzerweiterungen optimiert. FPU Mandel unterstützt HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) Architekturen.
FPU SinJulia

Diese Benchmark misst die 80-bit Fließkommaberechnungsleistung durch die Berechnung eines einzigen Frames eines modifizierten “Julia”-Fraktals. Der Code hinter dieser Benchmark ist in Assembly geschrieben und ist für alle bekannten AMD, Intel und VIA Prozessorkernvarianten mithilfe der trigonometrischen und expotenziellen x87 Befehlen optimiert. FPU SinJulia unterstützt HyperThreading, Multi-Prozessor (SMP) und Multi-Core (CMP) Architekturen.