

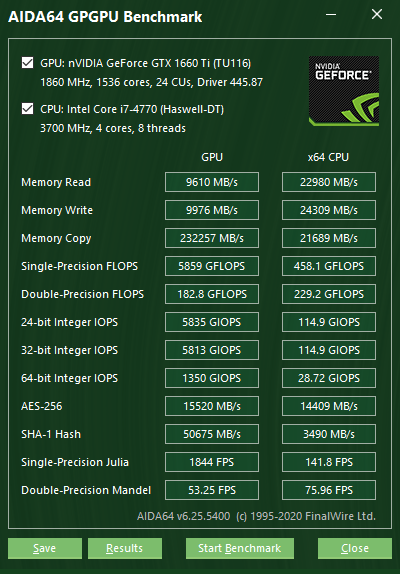
GPGPU Benchmark



Dieses Benchmark-Panel, das aus der Werkzeuge | GPGPU Benchmark gestartet werden kann, bietet eine Reihe von OpenCL GPGPU Benchmarks. Mit Hilfe dieser Benchmarks kann die GPGPU Leistung mit verschiedenen OpenCL Belastungen gemessen werden. Jede einzelne Benchmark kann auf bis zu 16 GPUs, darunter AMD, Intel und NVIDIA-GPUs (oder eine Kombination von diesen) betrieben werden. Natürlich werden Crossfire-und SLI-Konfigurationen sowie die beiden APUs und dGPUs vollständig unterstützt. Derzeit gibt es nur eine einleitende Unterstützung für HSA-Konfigurationen. Grundsätzlich kann jedes Gerät, das als ein GPU unter den OpenCL-Geräten aufgeführt ist, verglichen werden.
Aktuelle OpenCL-Benchmarks werden für keine GPU-Architekturen optimiert. Stattdessen verlässt sich das AIDA64 OpenCL Modul auf den OpenCL Compiler, der den OpenCL Kernel für die zugrunde liegende Hardware optimiert. Die für diese Benchmarks benötigten OpenCL-Kernel werden in Echtzeit erstellt (kompiliert), mit Hilfe der GPU OpenCL Treiber. Aus diesem Grund ist es empfehlenswert, alle Grafikkarten Treiber (Catalyst Forceware, HD-Grafiken, etc.), auf die neuesten Version zu aktualisieren. Für die Erstellung werden folgende OpenCL Compiler Optionen übergeben: -cl-fast-relaxed-math -cl-mad-enable.
Für Vergleichszwecke bietet das GPGPU Benchmark-Panel auch CPU-Messungen an. Allerdings verwenden die CPU-Benchmarks kein OpenCL, sie sind in nativen x86/x64 Maschinencode geschrieben und verwenden verfügbare Befehlssatzerweiterungen wie SSE, AVX, AVX2, FMA und XOP. Diese CPU-Benchmarks ähneln den alten AIDA64 CPU und FPU Benchmarks, aber jetzt messen sie die maximale Rechenleistung der Computer (FLOPS, IOPS). Die CPU-Benchmarks sind stark multi-threaded und sind für jede CPU-Architektur - seit dem ersten Pentium-Prozessor - optimiert.
Derzeit sind folgende Benchmark -Tests verfügbar:
Memory Read (Speicher lesen)
Misst die Bandbreite zwischen GPU und CPU. Die Leistung, wie schnell die GPU Daten aus dem eigenen Gerätespeicher in den Systemspeicher kopieren kann, wird gemessen. Wird auch als Geräte-zu-Host-Bandbreite bezeichnet. Die CPU Benchmark misst die Bandbreite, wie schnell der Speicher gelesen werden kann, das heißt, wie schnell die CPU die Daten aus dem Systemspeicher ausliest.
Memory Write (Speicher schreiben)
Misst die Bandbreite zwischen CPU und GPU. Die Leistung, wie schnell die GPU Daten aus dem Systemspeicher in den eigenen Gerätespeicher kopieren kann, wird gemessen Wird auch als Host-zu-Gerät Bandbreite bezeichnet. Die CPU-Benchmark misst die Speicher-Schreib-Bandbreite, das heißt, wie schnell die CPU die Daten in den Systemspeicher schreiben kann.
Memory Copy (Speicher kopieren)
Misst die Leistung der eigenen Gerätespeicher der GPUs. Die Leistung, wie schnell die GPU die Daten aus dem eigenen Gerätespeicher an eine andere Stelle in dem gleichen Gerätespeicher kopieren kann, wird gemessen. Wird auch als Gerät-zu-Gerät Bandbreite bezeichnet. Die CPU Benchmark misst die Bandbreite beim Kopieren im Speicher, das heißt, wie schnell die CPU die Daten im Systemspeicher von einem Ort zum anderen bewegen kann.
Single-Precision FLOPS
Misst die MAD (Multiply-Addition) Leistung der GPU, auch als FLOPS (Floating-Point Oberations Per Second = Fließkomma Berechnung pro Sekunde) bekannt, mit single-precision (32-bit, “float”) Fließkomma Daten.
Douple-Precision FLOPS
Misst die MAD (Multiply-Addition) Leistung der GPU, auch als FLOPS (Floating-Point Oberations Per Second = Fließkomma Berechnung pro Sekunde) bekannt, mit double-precision (64-bit, “double”) Fließkomma Daten. Nicht alle GPUs unterstützen double-precision floating-point Berechnungen. Aktuelle Intel Desktop und mobile Grafikkarten unterstützen zum Beispiel nur single-precision floating-point Berechnungen.
24-bit Integer IOPS
Misst die MAD (Multiply-Addition) Leistung der GPU, auch als IOPS (Integer Oberations Per Second = Integer Berechnung pro Sekunde) bekannt, mit 24-bit Integer (“int24”) Daten. Dieser spezielle Datentyp ist in OpenCL definiert, da viele GPUs in der Lage sind, int24 Berechnungen in deren Fließkomma Einheiten auszuführen. Damit wird die Integer Leistung effektiv von 3 zu 5 erhöht, wenn wir dies mit 32-bit Berechnungen vergleichen.
32-bit Integer IOPS
Misst die MAD (Multiply-Addition) Leistung der GPU, auch als IOPS (Integer Oberations Per Second = Integer Berechnung pro Sekunde) bekannt, mit 32-bit Integer (“int”) Daten.
64-bit Integer IOPS
Misst die MAD (Multiply-Addition) Leistung der GPU, auch als IOPS (Integer Oberations Per Second = Integer Berechnung pro Sekunde) bekannt, mit 64-bit Integer (“long”) Daten. Die meisten Grafikkarten haben keine speziellen Ausführungsressourcen für 64-bit Integer Berechnungen. Solche Geräte emulieren 64-bit Integer Berechnungen auf den 32-bit Integer Ausführungseinheiten. In solchen Fällen kann die 64-bit Integer Leistung sehr gering sein.
AES-256
Man kann diese OpenCL-basierte GPGPU benchmark verwenden um die Performance der AES-256 Verschlüsselung auf modernen Grafikprozessoren und APUs zu messen.
SHA-1
Man kann diese OpenCL-basierte GPGPU benchmark verwenden um die Performance des SHA-1 hashing auf modernen Grafikprozessoren und APUs zu messen.
Single-Precision Julia
Misst single-precision (32-bit, “float”) Fließkomma Leistung durch Berechnung einiger Frames des bekannten “Julia” Fractals.
Double-Precision Mandel
Misst double-precision (64-bit, “double”) Fließkomma Leistung durch Berechnung einiger Frames des bekannten “Mandelbrot” Fractals. Nicht alle GPUs unterstützen double-precision floating-point Berechnungen. Aktuelle Intel Desktop und mobile Grafikkarten unterstützen zum Beispiel nur single-precision floating-point Berechnungen.
Benutzeroberfläche des GPGPU Benchmark Panels
Man kann die Kontrollkästchen verwenden, um ein GPU Gerät oder die CPU für die Benchmarks auszuwählen. Der Zustand des Kontrollkästchens für CPU wird nach dem Schließen des Panels gespeichert.
Benchmarks für die ausgewählten Geräte können durch Klicken auf die "Start Benchmark" Taste gestartet werden. Wenn man alle Benchmarks ausführen möchte, aber nur auf GPU(s), dann muss man auf die GPU Spaltenbeschriftung doppelt klicken. Wenn man nur die Speicherlese Benchmarks sowohl auf GPU(s) als auch auf der CPU ausführen möchte, muss man auf das Label “Memory read” doppelt klicken. Wenn man die “Memory Read” Benchmark nur auf GPU(s) ausführen möchte, muss man auf die Zelle doppelt klicken, in der das angeforderte Benchmark Ergebnis angezeigt wird, wenn der Benchmark abgeschlossen ist.
Die Benchmarks werden gleichzeitig auf allen ausgewählten Grafikprozessoren mit mehreren Threads und mehreren OpenCL Kontexten ausgeführt, jeweils mit einer einzigen Befehlwarteschlange. CPU-Benchmarks sind jedoch nur dann gestartet, wenn die GPU Benchmarks abgeschlossen sind. Es ist derzeit nicht möglich, GPU und CPU Benchmarks gleichzeitig laufen zu lassen.
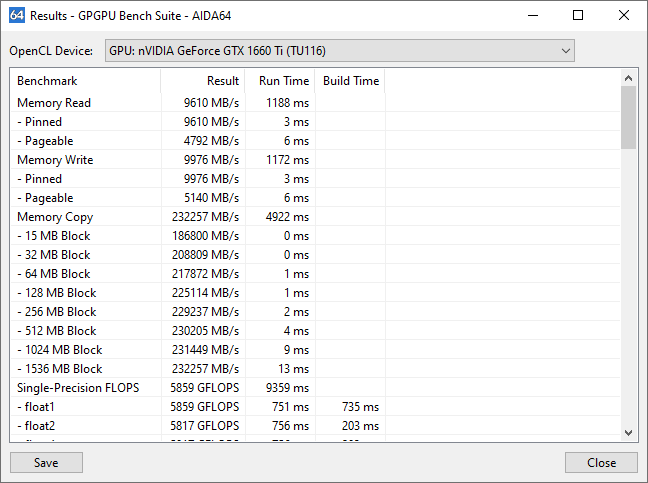
Hat das System mehrere GPUs, wird die erste Ergebnisspalte ein zusammenfassendes Ergebnis für alle Grafikprozessoren anzeigen. Individuelle GPU Ergebnisse werden kombiniert (addiert) und die Spaltenbeschriftung wird zum Beispiel so aussehen: "4 GPUs". Wenn man einzelne Ergebnisse überprüfen möchte, kann man entweder nur eine GPU auswählen oder auf die Schaltfläche “Results” klicken, um das Fenster für die Ergebnisse zu öffnen.
Hat man zwei GPUs, deaktiviert man aber das Kontrollkästchen für CPU Test, wechselt das Panel in Dual-GPU-Modus, in dem die erste Spalte für die Anzeige der Ergebnisse für GPU1 verwendet wird und die zweite für GPU2. Wenn man die kombinierte Leistung der beiden GPUs sehen will, wählt man einfach die Checkbox für CPU Test wieder aus nachdem die Benchmark beendet ist und das Panel wechselt wieder in den Standard-Layout zurück.